Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
西湖大学 于开丞老师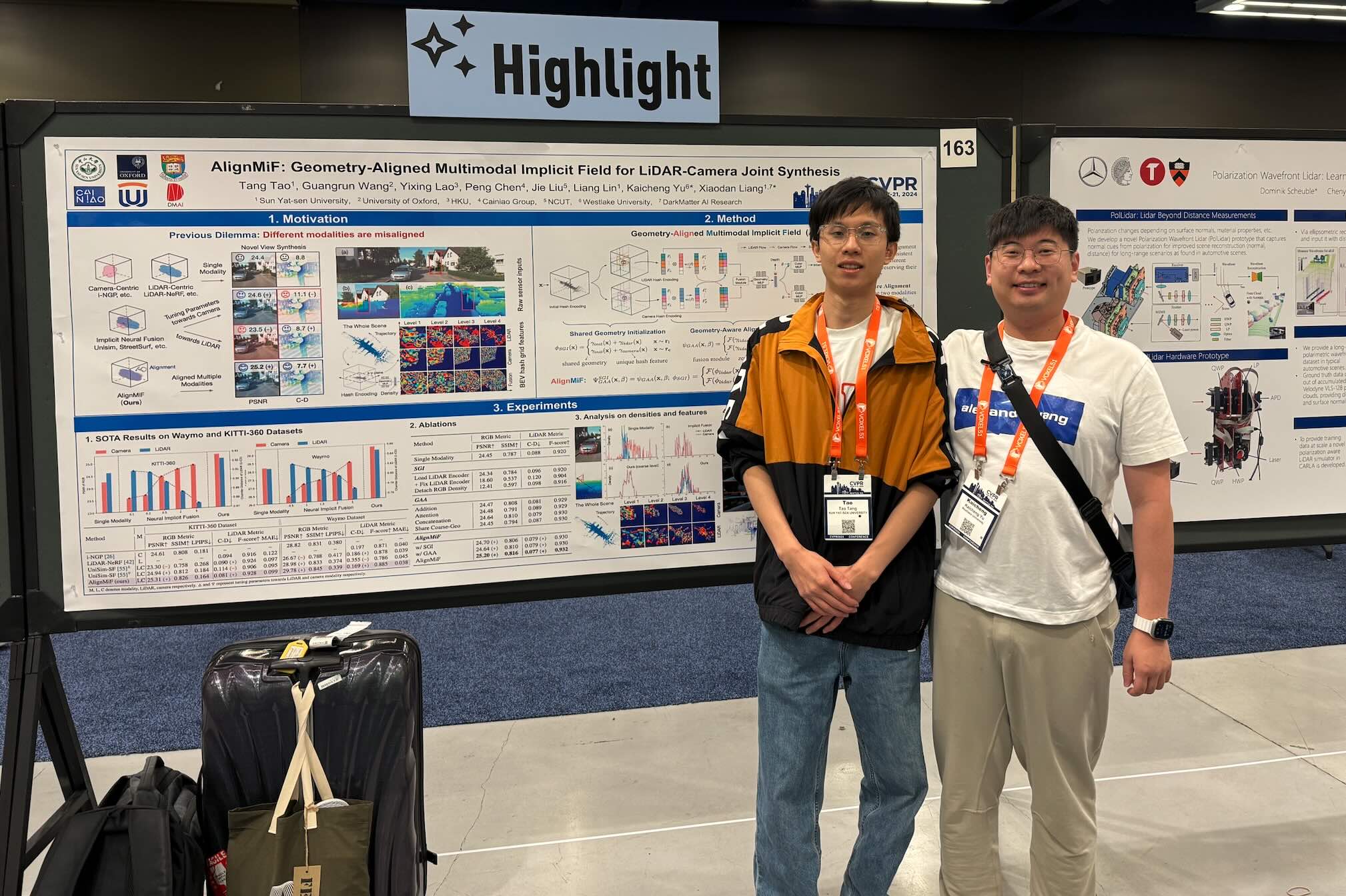
硕凡导师 
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published in , 1900
Download here
Published:
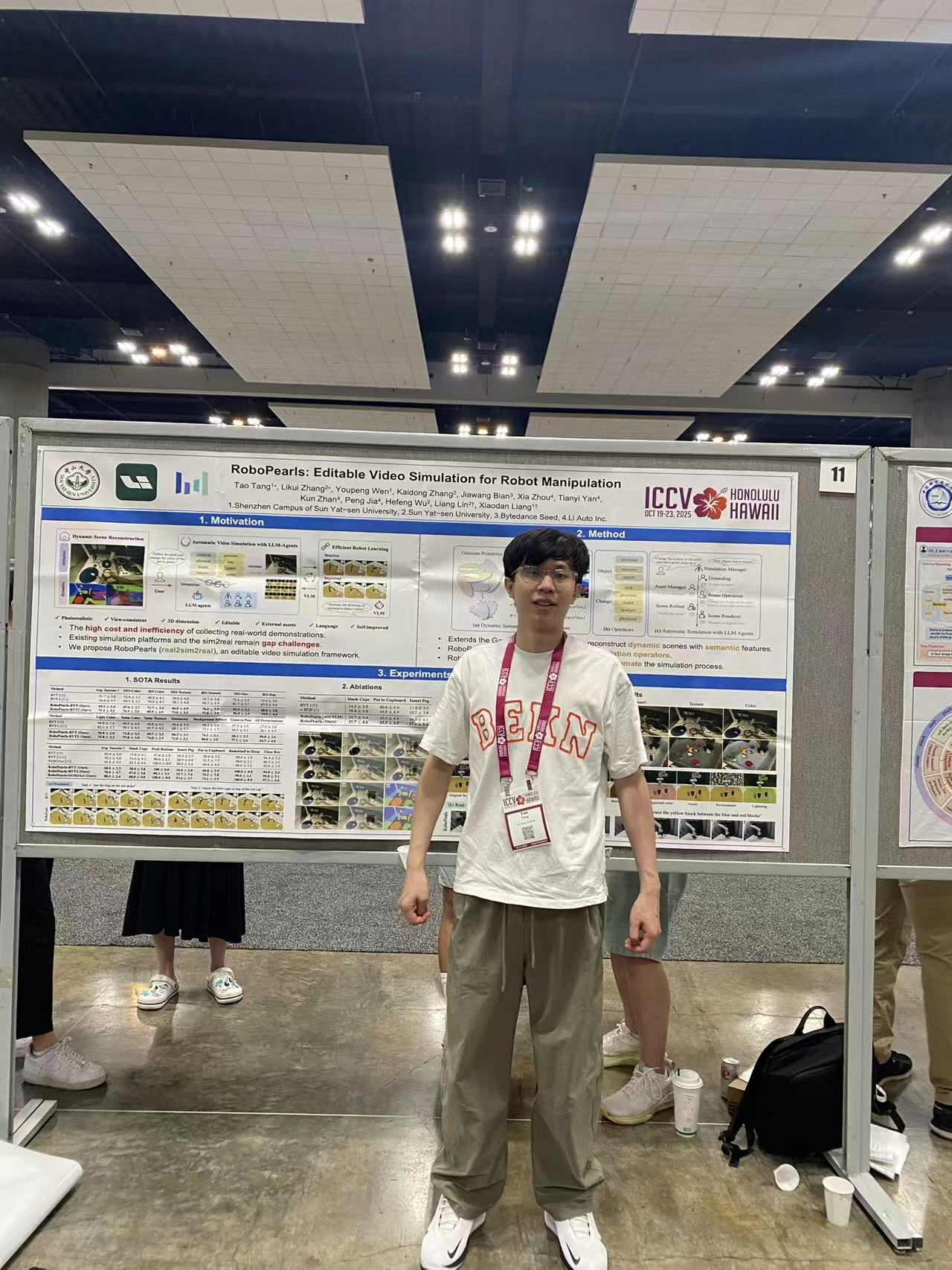
神经网络结构搜索和自监督学习:1) 提出结构搜索方法 BossNAS,通过分块自监督机制缓解权重共享空间过大 和监督偏差问题,显著提升模型排序准确性与搜索效果。 2) 设计自动化自监督视图生成方法 AutoView,避免繁琐手工视图设计,以对抗方式最小化视图间互信息;提出自约束损失函数,联合优化互信息以提升自监督学习。
Published:
自动驾驶 多模态感知: 1) 主导构建 RobustBenchmark,收集 BEV 感知中常见噪声干扰样例,开发系统化鲁棒 性测试工具包;在 nuScenes 和 Waymo 上建立新鲁棒性基准,全面评估主流 BEV 融合方法的抗干扰性能。2) 参与 BEVFusion 框架设计:采用独立网络分别编码雷达与图像特征,统一投影至 BEV 空间再进行融合,实现近似 后融合的结构,打破视觉对雷达的主导依赖。 3) 参与设计 BEVHeight:为提升检测在参数扰动下的稳定性, 提出以目标高度回归替代直接深度预测,通过几何转换间接获取深度,显著缓解相机参数扰动对性能的影响。4) 参与开发 Opensight:提出基于 LiDAR 的开放词汇检测框架。通过图像生成通用 2D 检测框并回投至 LiDAR 空间估计 3D 位置;设计跨模态对齐与融合模块,将 3D 与 2D 特征对齐后进行语义解码,实现开放类目标检测能力。
Published:
• 自动驾驶场景 多模态生成: 1) 参与设计 Delphi,一种基于扩散模型的长视频生成方法,引入跨视角共享噪声机 制与特征对齐模块以增强空间与时间一致性。 2) 提出首个端到端多模态场景生成框架 OmniGen,在统一 0-BEV 表征中融合 LiDAR 与图像,通过扩散模型生成多模态数据。 3) 提出 BEV-TSR,首个基于 BEV 空间的文本场 景检索框架,结合知识图谱与大语言模型增强语义理解,实现高精度多模态检索。